What is our Text Data Services?
AI Data Lens Ltd.-Text Data Services: Given the broad text data services, collection, labeling, and processing of textual information for AI and machine learning applications are an end-to-end suite of services provided. Equipped with a comprehensive suite of text data services, our services support businesses to build and curate NLP models that understand, classify, and generate text. We support industries ranging from finance and healthcare to customer service and everything in between. Our expertise ensures that your AI systems are trained on diversified high-quality text information, which empowers them to achieve tasks like language understanding, translation, and conversation at a high degree of accuracy.
Text Data Collection:
Our Text Data Collection service gathers huge, quality textual datasets from different sources. We gather diverse multilingual data that fits your AI training needs, enhances model performance responsible for natural language understanding, text generation, or search algorithms in a wide range of domains using various languages.
Text Annotation:
Basically, Text Annotation is the process by which text data will be labeled with metadata, including entities, sentiment, or parts of speech. The service plays a decisive role in training AI models for the most important tasks of NLP, allowing them to perceive and process text better in further applications, such as chatbots, sentiment analysis, or question-answering systems.
Text Classification:
Text classification is a task of text assigning to classes based on predefined categories: spam detection, topic identification, or intent recognition. Then, this service will become vital in industries like customer service or content moderation because the AI systems should sift sooner through many huge texts.
Text Sentiment Analysis:
The Text Sentiment Analysis can detect and analyze sentiments from texts and identify whether it is positive, negative, or neutral. A service such as this will be important to customer experience management, analysis of product feedback, and social media monitoring, where the extraction of their feelings and opinions could lead to business decisions.
Named Entity Recognition (NER):
Named Entity Recognition identifies the proper nouns in text and categorizes them into a name of a person, organization, or place. This service is crucial for extending the capability of search engines, recommendation systems, and chatbots by allowing AI models to know exactly the important components within the text.
Question-Answering Data:
Question-Answering Data develops datasets that allow AI models to answer questions based on context. This is specifically useful for virtual assistants, search engines, and educational platforms needing to provide clients with very specific answers to their queries.
Summarization Data:
Summarization allows AI models to summarize long texts into shorter summaries with key information retained. News aggregators, research, and customer support tools find this service of high value because it helps save time when providing the most important details in large amounts of text.
Document Classification:
Document classification entails categorizing whole documents based on their content. These usually involve legal, financial, or medical documents. Thus, the service is very important in industries such as law firms, health care, and financial businesses where AI models have to categorize and put together huge volumes of documentation.
Text-to-Speech Data:
As a result, Text-to-Speech Data can provide training for AI with the necessary datasets needed to have written text spoken in natural-sounding speech. This service indeed plays a key role in developing voice assistants, audiobooks, and tools used for accessibility, where accurate speech synthesis is inevitable.
Text Generation Data:
Text Generation Data provides AI models with the ability to create coherent, contextually relevant text. The service is particularly handy in applications such as content creation, chatbots, and automated report writing, among other areas, where human-like text generation increases considerably in effectiveness and naturalness.

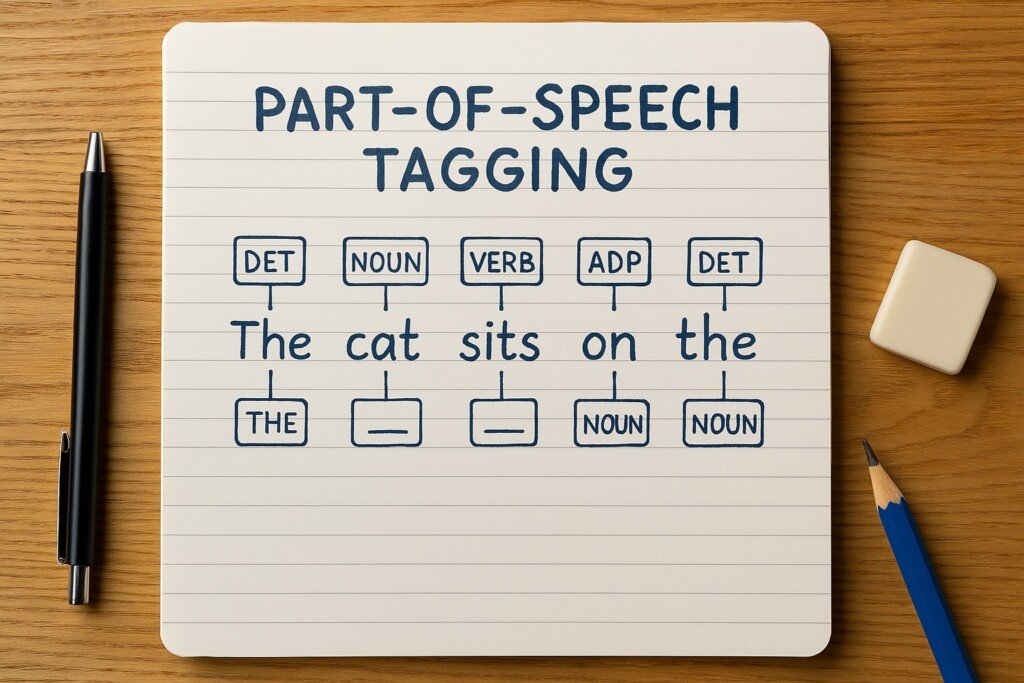
Part-of-Speech Tagging:
Part-of-Speech Tagging either means labeling every word in a text with its grammatical category, like a noun, verb, or adjective. It is crucial service for the NLP models, therefore helping them understand sentence structure, which again improves the performance in translation, text generation, and syntactic analysis.
Language Model Fine-Tuning Data:
The fine-tuning data by the Language Model provides specialized datasets to fine-tune pre-trained language models for specialized tasks. This service is highly important in enabling improved advanced accuracy of the language models in domain-specific applications, including but not limited to such areas as legal, medical, or financial text analysis.
Conversational AI Training Data:
Conversational AI training data provides an AI system with dialogue comprehension and generation capabilities, therefore enabling the AI to have organic conversations with humans. The service is quite important because high-level chatbots, virtual assistants, and customer services that deal in deep contextual conversations depend on it.
Text Style Transfer Data:
The Text Style Transfer Data can be used to change the style of a given text by an AI model while maintaining its meaning. This service will turn out pretty useful in content creation applications where models have to paraphrase texts into different tones or styles, ranging from formal, casual to creative writing.
Chatbot And Dialogue Systems Data:
Data The data assisting chatbots and dialogue systems are structured datasets that build AI models to manage and navigate the conversation with users. This service is indispensable in developing customer support bots, personal assistants, and other conversational AI systems that provide effective, human-like interactions and solutions to any problem.