What is our Data Annotation Services?
AI Data Lens Ltd. annotates all types of data, from audio to video, images, and text, with precision to feed into training of AI models. Our strong annotation solutions will give rise to AI that will recognize objects, people, and context in everything from self-driving cars to uses in healthcare, retail, and security. From basic labeling to complex attributes annotation, we make sure that the datasets provided are fully optimized and capable of training AI models more precisely, efficiently, and on wider scales. Leveraging global expertise, we’re geared up to serve a wide array of industries with topmost quality annotation services across the globe.

Audio Annotation:
Audio annotation adds metadata information to the audio file, segmenting it with speaker IDs, emotions, or acoustic events. This is quite important in training AI models for speech recognition, emotion detection, and the analysis of environmental sounds since such would help them in telling apart different audio cues with precision.
Video Annotation:
Video annotation includes the labeling and tagging of objects, people, or actions in videos. Video annotation is one of the most important services, not only for autonomous vehicles and surveillance but also for applications related to media analytics, where AI models will have to detect and track elements within video footage in real-time.


Image Annotation:
Image Annotation offers diverse, labeled images that instruct AI object detection, facial recognition, much more. Our high-quality annotations include bounding boxes, keypoints, and other challenging annotations, giving AI systems a way to read image information with the accuracy necessary for healthcare, retail, and security.
Text Annotation:
In Text Annotation, the texts are labeled with metadata such as entities, sentiment, and part-of-speech tags. These annotations have been so important in NLP applications: chatbots, systems of machine translation, search engines, and any other AI-based system that has to process and understand the structure of text data.




3D Data Annotation:
3D Data Annotation labels three-dimensional data, such as LiDAR or point cloud data, representing the models that make things work for autonomous vehicles, robotics, and geospatial analyses. This allows models to interpret depth and spatial relationships enabling them to navigate complex real-world environments.
Semantic Segmentation Annotation:
Semantic Segmentation Annotation segmentizes images or video frames into distinct regions, labeling every pixel with a particular class. This is a very relevant service that enables detailed analysis in autonomous driving, medical imaging, and even environmental monitoring, where literally the understanding of context and location for each and every object is necessary.




Bounding Box Annotation:
Bounding Box Annotation involves drawing boxes around objects in images or video frames, hence the generation of AI models that can detect and classify the objects. Thus, applications in common areas will be found through self-driving cars, surveillance, and e-commerce, all these being one of the primary functions.
Keypoint Annotation:
Keypoint Annotation labels specific points of interest within an image, such as facial landmarks or joints in human pose estimation. The service is indispensable in many application fields like face recognition, people activity tracking, and medical diagnosis, which absolutely require accurate points of reference.



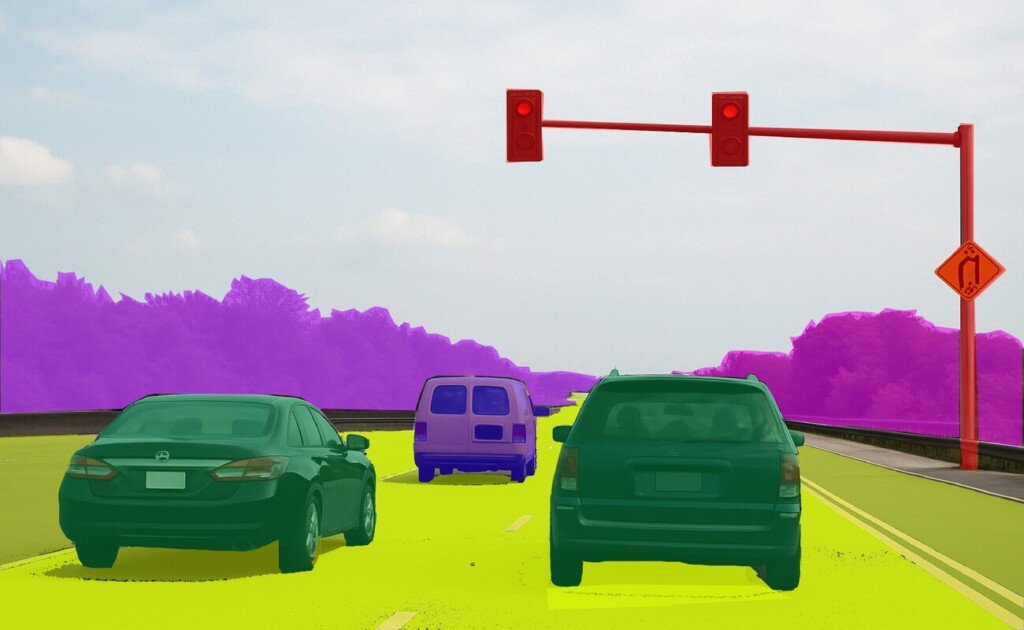
Polygon Annotation:
Polygon annotation involves the drawing of polygons around objects with irregular shapes for more precise labeling. Such a procedure becomes essential in applications related to the processing of aerial images, like the case of capturing buildings or topographic features that are not possible using simple shapes.
Instance Segmentation:
Instance segmentation not only identifies object classes but also distinguishes between different instances of the same class. That makes this service highly valuable for applications such as autonomous vehicles and medical imaging, where AI models need to identify and distinguish between multiple objects in one image of the same type.

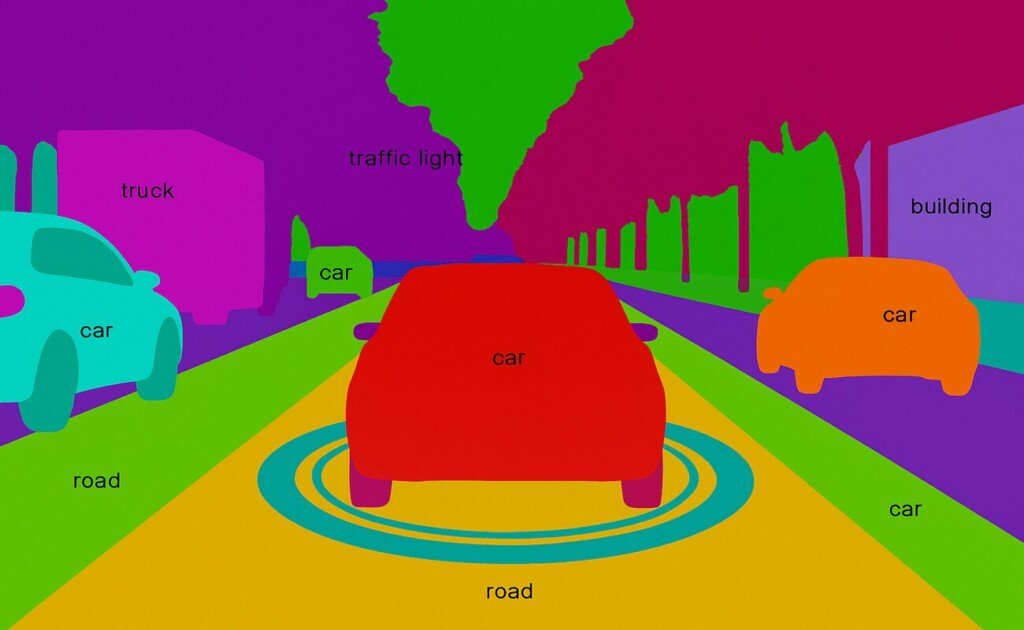


Landmark Annotation:
Landmark annotation refers to the tagging or labeling of specific locations or objects in images, such as facial landmarks and geographic points. Landmark annotation is an important service for face recognition applications, mapping technologies, and geospatial analysis, where accurate localization of landmarks plays a very important role in navigation and analysis.
Named Entity Recognition (NER) Annotation:
The annotation of Named Entity Recognition involves labeling certain text entities like names, dates, and organizations. This service is mainly necessary for NLP applications like search engines, chatbots, and information extraction systems whose value lies in recognizing entities in text.
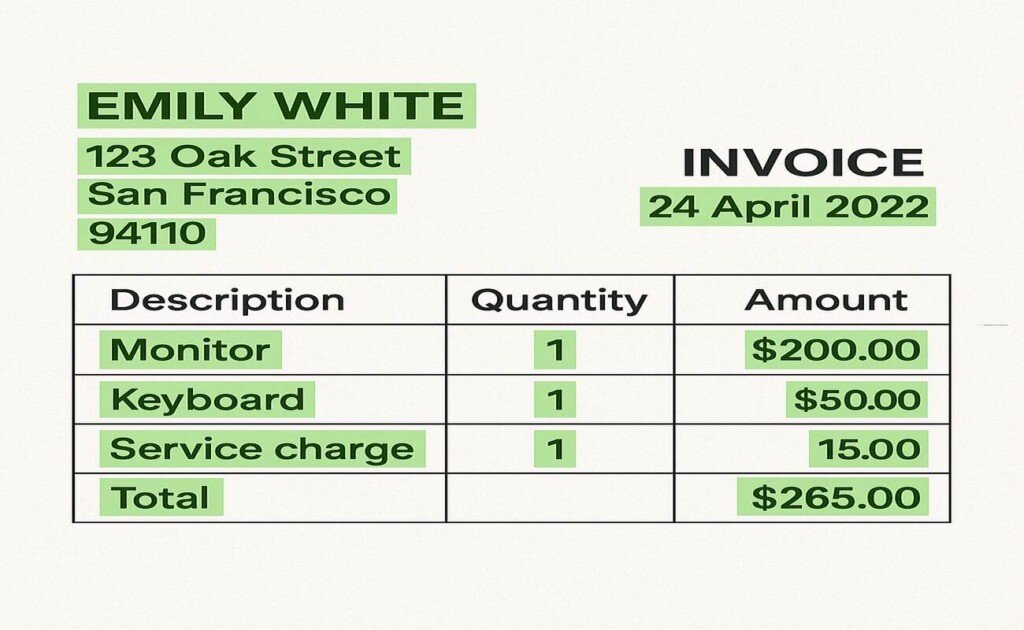


Temporal Annotation Video and Audio:
Temporal annotation is performed on the videos or audio streams to enable the AI system to identify any form of action or event being executed at a certain point in time. This allows for various important applications to be enabled: video surveillance, action recognition, and event detection.
Frame-by-Frame Video Annotation:
In frame-by-frame video annotation, detailed labeling is done for every frame in a video, hence enabling the precision in object detection and tracking. It is indispensable when it involves applications like self-driving cars, security, and analytics from videos, where accuracy and coherence across frames are highly needed to train reliable AI models.



Complex Attribute Annotation:
In complex attribute annotation, not actual objects but more abstract features such as emotions, gender, or sentiment are labeled in text, video, or audio data. This service is highly valued by all AI models serving customer service, social media analysis, and human behavior on the go since these provide deeper meanings with respect to contexts.